Loss function
The loss function is a modified version of the VAE loss, the negative ELBO. It has following parts:
- Reconstruction loss (): measures how well the autoencoder (encoder-decoder) is able to reconstruct the data, compares with .
- Consistency loss (): measures how well the encoded states and the DSR-generated states align in the latent space, compares with .
- Encoder entropy loss (): regularization loss encouraging the encoder to learn a meaningful latent distribution instead of a deterministic encoding.
- DSR loss (): measures how well the decoded DSR-generated trajectory aligns with the observation, compares with .
What the loss terms compare can be seen from the model schematic below.
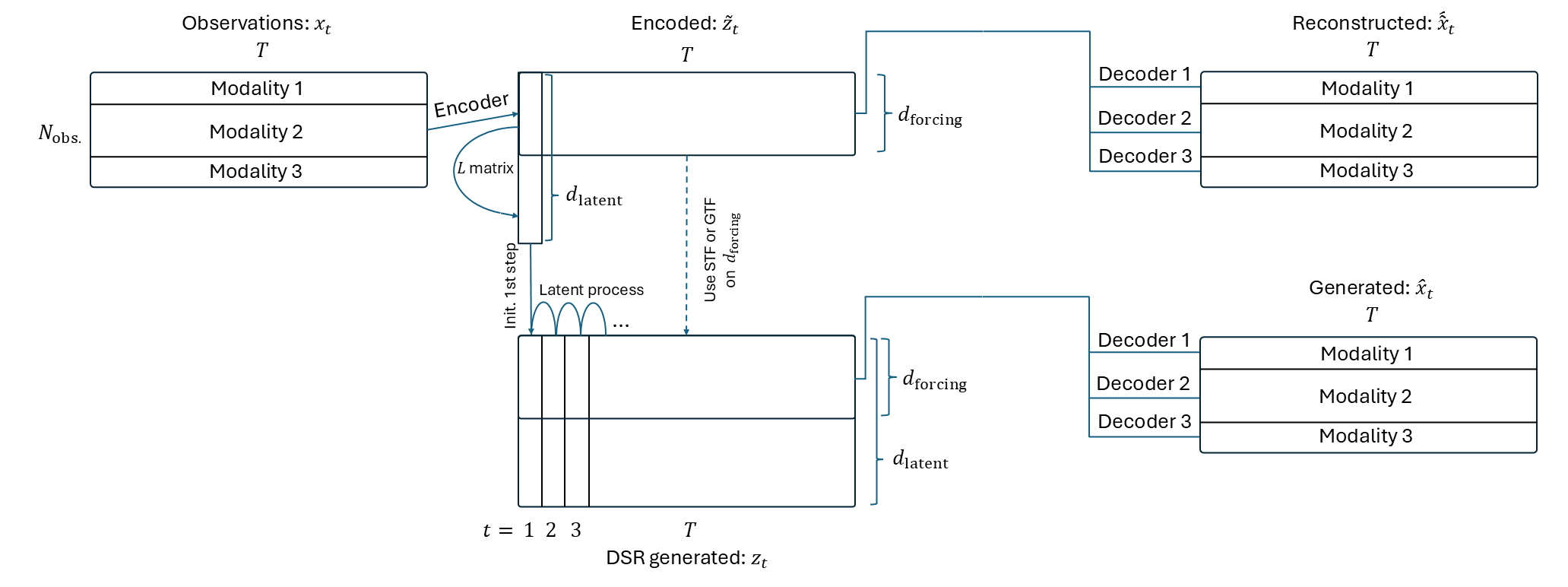
As the model is based on a VAE, the loss does not actually compare the reconstructed/generated observations with the true observations directly. Instead it uses calculates the log likelihood of the encoded/generated states given the decoder distribution.
Scaling of loss terms
Each loss term above, as well as additional regularization losses can be scaled to match the desired effect. This means that the total loss is weighted sum of all loss terms. This can be done using the value_scheduler, which does not only allow for setting the scaling, but also to increase or decrease the values throughout the training. The value scheduler expects a dictionary, where each loss term is assigned a unique key, which contains the initial value and optional scheduling for that term. For the concrete options please refer to the related documentation.
All standard loss terms have their function and are important for good results, as has been shown in Brenner, Hess et al. (2024). Their scaling still carries imporance: as the encoder provides the initial state and the teacher forcing signal to the latent model, having a good reconstruction is necessary for these to be informative. But if the reconstruction loss overpowers the DSR and consistency terms, the latent space may not contain enough structure for the DSR model to fit meaningful dynamics.