Dataset setup
Data structure
The data is expected to be in the following folder structure:
- base_path
- measurement_folder_1
- observations
- modality_1
- modality_2
...
- externals (optional)
- modality_1
- modality_2
...
- measurement_folder_2
...
where measurement_folder_1, measurement_folder_2 and modality_1, modality_2 are placeholders for the actual names of the folders and files, while observations and externals are expected to be the names of the folders containing the data modalities.
The names of the measurement folders and modality files play an important role for measurement- and modality-specific configuration of the ubermain, thus it is advised to give clearly identifiable names. These names are referred to as measurement_id and modality_id later in the documentation.
Each modality is expected to be a file containig python list of numpy arrays which was saved using the pickle module. Each numpy array encodes a continuous timeseries, with shape (len_timeseries, n_features).
Within one modality the timeseries may be of different lengths, but the number of features has to be the same for all of them. Furthermore different modalities of a timeseries must share the same length, but may have different number of features.
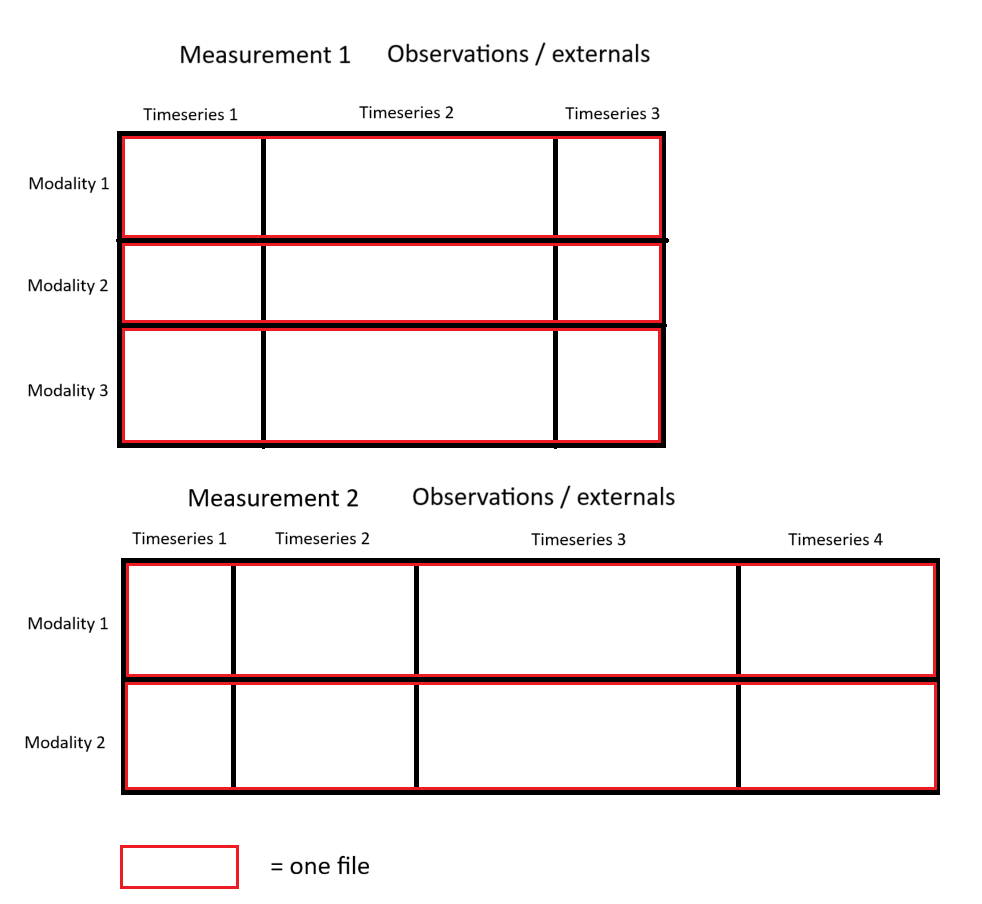
The picture above illustrates the expected data format of the observations/expected data folder, with red squares indicating the data expected to be present in one file. Width of each timeseries represents its length, while the height represents the number of features.
Standardization of input data
As is standard practice in ML, the dataset should be standardized for all normal distributed modalities. Other modalities, such as counts or categories cannot be standardized without changing the distribution completely.
Configuration parameters
The ubermain contains a bunch of parameters connected to the dataset.
base_path (str): The base path of the dataset to be used.measurement_folders (list[str]): The folders in the based path to be used in the experiment.excluded_filenames (list[str]): The filenames to be ignored in any of the measurement folders.test_timeseries_indices (dict[str, list[int]]): The timeseries indices put aside for evaluation, not used for training. Each dictionary entry corresponds to a measurement, the key is ameasurement_id, the value contains the timeseries indices.train_test_split (float): In some cases whole timeseries cannot be left out of training. In these cases only the test timeseries are split using this ratio. For the details on when this can happen see the corresponding page.evaluation_test_timeseries_indicesandevaluation_train_timeseries_indices (dict[str, list[int]]): The codebase features internal evaluation made during training. These two parameters configure which timeseries are used for evaluation. Note that if not set, they default to the whole train and test set, which for large datasets can result in long evaluation periods during training.